Ken Perlin
In a few years, when everyone gets used to wearing those future extended reality glasses in public spaces, text will be everywhere. Sometimes it will appear very large and looming against the sky. At other times it will show up on a convenient wall.
Then there is the text that will be hovering between you and me during our casual conversation (perhaps when ordering from a restaurant, or spending time together reading an email from Mom). And then there will be text we carry with us, as a personal note or reminder, which nobody else can see.
What exactly will this text look like? Will it be bright and glowing? Will it look flat or three dimensional? Will preferred fonts be cartoonish or formal? Will it aim to grab our attention, or to blend unobtrusively into our physical world?
These are not really questions about technology, but about human preference. Let’s say it’s twenty years in the future, and everyone, to borrow a term from Verner Vinge, is wearing. That is, we all have our cyber-contact lenses, and we take for granted that we can all have augmented reality floating in the air between us.
Seeing text from both sides
Now suppose that you and I want to discuss some text. If the text document just floats in the air between us, then either (1) we each see the document the right way forward, or (2) one of us will see it backwards. The problem with the first scenario is that if I point to or look at some part of the document, the place where I’m pointing or looking won’t correspond to what you see there.
More than thirty years ago, Hiroshi Ishii handled a similar issue very cleverly in his ClearBoard interface. People interacted face to face through a video screen. The video flipped everybody’s image left/right, so that you always saw the other person in mirror-reverse. This meant that we could both look at the same document floating between us, and everything worked out — text was forward for both of us, and our gaze directions always matched. This is the paradigm that has now been widely adopted by video chat software such as Zoom.
But you can’t do that if you’re physically face to face with somebody. One possibility is that people will just learn to read backwards, but somehow I doubt that this will catch on — from a social perspective, the situation is just too asymmetric.
Another possibility is that augmented reality will use a convention that text runs vertically, rather than horizontally. We can already read vertical text just fine, so this won’t require any new skills or training. The left right reversal will take place within each character. For example, we will both see the letter “E” rather than one of us seeing the letter “∃“.

The text between us could even function as an AI-enhanced text editor. You can talk to it or type into it, just like an ordinary text editor. Meanwhile, an AI is always running. The AI looks for certain things you might enter, and responds in smart ways. For example, you might enter “make a table of this year’s Google monthly stock price.” In response, your AI will replace the text you just entered by the appropriate table. A text editor with that sort of capability would be useful in many fields, including art, science, music, engineering and the humanities. The possibilities are endless.
Seeing text that is far away
If text is going to be visible everywhere in our physical world, then there will be times when that text will be far away from where we are, and will therefore appear very small. Yet ideally, we would still want it to be readable. One solution is to create a font that looks one way when you are near, and another way when you are far away. Below to the left is a font that I created out of triangle strips, which render very efficiently in modern GPUs. This approach has an advantage over the more traditional texture-atlas based fonts in that a very large quantity of text can be displayed in 3D without slowing down the rendering. Below to the right is the same font as it is seen when very far away (and therefore visibly tiny). Based on distance, we vary the visible thickness of the triangle strips via math in the GPU fragment shader. By using this approach we can create text which remains readable from a distance of several hundred times the size of interline spacing.

Another fun solution is to create a custom font specifically optimized for being readable at very small sizes. Here is an example of such a font, which I created just out of curiosity. Each text character is only four pixels high, so you can cram a very large amount of text into a tiny space. Here is what the alphabet looks like:

And here are the opening paragraphs of A Tale of Two Cities by Charles Dickens.

The evolution of Future Language
Meanwhile, if we flash forward about thirty or forty years from now, several generations of children will have gotten used to using augmented reality gestures to talk with each other. Because these kids spent time with these interfaces before they were seven, they have incorporated into their everyday natural language the ability to draw shapes in the air, create virtual objects through gesture, and navigate a space that mixes the physical with the virtual.
As much research has shown, natural language is actually created by little kids, including natural languages with a strong visual component. Most grown-ups never quite master this new kind of natural language. They can usually muddle through, using some kind of pidgin as a serviceable approximation, although they make all kinds of grammatical errors that the kids find funny.
But a generation or two after that, those kids will have grown up, and nearly everyone will be a native speaker of our future language. We might call this Future Language. What I mean by Future Language is how language itself will evolve in a future where ubiquitous mixed and augmented reality, supplemented by AI, will be an everyday part of life.
Children growing up in such a world will create shared visual representations of thought by gesturing in the air with their hands. To children born into that reality, this will simply be taken for granted, the way we now take for granted the ability to text or speak on the telephone.
Such forms of visual communication will not replace verbal speech. Rather, they will augment it, allowing speech itself to be used in new ways — much as phone and text have not replaced speech, but rather have extended its reach, allowing it to be used and shared in ways that have altered the way we communicate.
Meanwhile, although technology continues to evolve, we are still stuck with the brains we have, which have not changed in any fundamental way for the last 30,000 years. So when we look at using our hands, in combination with any forthcoming mixed reality technology, to “create things in the air”, we should look at how humans gesture naturally. Let’s focus specifically on gestures made with the hands (as opposed to, say, nodding, shrugging the shoulders, etc).
There are four basic kinds of meaning people usually create with hand gestures: symbols, pointing, beats and icons. Symbols are culturally determined. Some examples are waving hello, fist bumping, crossing fingers, or shaking hands.
We usually point at things while saying deictic words like “this” or “that”. Beats are gestures we make while talking, usually done without really thinking, like chopping hand motions. Beats come so naturally that we even use them when talking on the phone.
Finally, icons are movements we make during speech which have a correlation to the physical world. Examples are holding the hands apart while saying “this big”, rubbing the hands together while talking about feeling cold, or holding out one hand palm down to indicate height.
Some of these types of gestures are going to be more useful than others in adding a computer-mediated visual component to speech.
In addition to symbols, pointing, beats and icons, we will have the ability for all participants in a conversation to see the results of their gestures, perhaps as glowing lines floating in the air.
As we think about how to use our gestural tools, it is important to remember that we are not trying to replace verbal speech, but rather to augment it. The situation is somewhat analogous to having a conversation at a whiteboard. As each participant speaks, they draw pictures that help clarify and expand upon the meaning of their words.
One key difference is that if you have an AI in the loop, the lines you draw can spring to life, animating or changing shape as needed. You are no longer stuck with the static pictures that a whiteboard can provide.
For example, if you are trying to convey “this goes there, then that goes there”, you can do better than just draw arrows — you can actually show the items in question traveling from one place to another. Which means that if you are trying to describe a process that involves asynchronous operations (for example, a cooking recipe), your visualization can act out the process, providing an animated representation of the meaning that you are trying to convey.
So how do we use symbols, pointing, beats and icons to make that happen? How do we use gestures to create visible representations, as a way to augment conversational speech? To break this down into different types of gestures, we should refer back to the reasons we already use various types of gestures.
Pointing is easy. Anything we have visually created can be pointed to, while saying words like “this” or “that”. Also, we can point at one item and then at another to establish a relationship between the two objects.
If we have drawn anything that has a process component, beat gestures are a natural way to iterate through that process. Beat gestures are essentially a way of saying “here is the next thing.”
There is an interesting relationship between pointing and beat gestures when it comes to describing time-varying processes: To go back to our cooking recipe example, we can use pointing to refer to a particular place in the recipe. Then we use beat gestures to advance step by step through the recipe instructions.
When used to augment speech, symbols essentially act as adverbs. For example, we can use symbolic gestures to make it clear that things are happening fast or slow, calmly or with agitation, definitively or with confusion, or in a friendly or hostile manner.
Lastly, icons, particularly when used in tandem with spoken words, can be used to create visual representations of actual topics of conversation — a chair, a tree, a calendar, the Sun. Because we are speaking while gesturing, we don’t actually need to draw the objects under discussion. Rather, we can use iconic gestures to indicate a location and size for the visual representation of each object or concept under discussion.
In addition to relying on speech to fill in the meaning of iconic gestures, it will also be useful to provide each conversant with the option to sketch specific shapes in the air while speaking. This would be helpful in situations where a physical shape contributes strongly to the intended meaning of the speech act.
For example, saying the word “time” while drawing a rectangle might result in a calendar, whereas saying the same word while drawing a circle might result in a clock. In each case, the drawn shape acts as a modifier on the spoken word, lending it a more context-specific meaning.
It will also be useful to distinguish between three ways to gesture with the hands: one-handed, symmetric two handed, or asymmetric two-handed.
An example of a one-handed gesture would be: Close the fist on a visual icon, move the hand, and then release the fist, which could be a way to indicate: “I move this to over there.”
An example of a symmetric two-handed gesture would be: Hold the two hands open with palms facing each other so that an icon is positioned between them, then spread the hands further apart, which could be a way to indicate “Let’s zoom in on this to see more detail.”
An example of an asymmetric two-handed gesture would be: Close the fist of one hand on an object, then pull the other hand, with fist closed, away from the first hand, which could be a way to indicate: “Let’s make a copy of this.”
The foregoing gesture examples may all seem plausible, but that doesn’t make them correct. “Correctness” in this case means whatever is naturally learnable.
Linguists have a very specific definition for the phrase “naturally learnable”. It doesn’t mean something that can be learned through conscious practice and study. Rather, it means something that one learns even without conscious practice or study.
For example, one’s native spoken language is naturally learnable. We didn’t need to go to school to learn our first spoken language — we began to gradually speak it when we were still young children, simply by being exposed to it.
In contrast, written language is not naturally learnable. Most people need to put in the effort required to consciously study and practice before they can read or write effectively.
Attempts to create a synthetic “natural language” generally fail, in the sense that children will not learn them. For example, when children are exposed to Esperanto, they will spontaneously try to alter it, because its rules violate their innate instinct for natural language.
There is now a general consensus amongst evolutionary linguists that natural language and children below around the age of seven are a co-evolution: Natural language evolved to be learnable (and modifiable over time) by little children, while simultaneously little children evolved to learn and modify natural language.
Ideally we want our augmentation of language to be naturally learnable. But how can we do such a thing?
Suppose we were to put together a committee of the smartest and most aware linguists. Alas, any gestural vocabulary or grammatical rules proposed by such a committee would be doomed to failure.
The adult mind simply cannot determine what is naturally learnable. Otherwise, millions of people would now be speaking that carefully constructed and beautifully rational language Esperanto.
The key is to allow our language extensions to be designed by little children. One might object that little children are not equipped to program computers.
Yet we can get around that objection as follows: Let us assume, thanks to forthcoming augmented reality technology, that little children can see the results of gestures they make in the air.
We can then observe the corpus of gestures those children make as they converse with one another, using machine learning to help us categorize that corpus. Initially we put only the most basic of behaviors into the system.
For example, a spoken word might generate a visual representation of that word (eg: saying the word “elephant” would generate a cartoon image of an elephant). Also, as children point or reach toward various virtual objects floating in the air, we might highlight those objects for them.
We then gather information from how they use this basic system to tell stories. As we do this, we aim to interfere as little as possible.
As we observe patterns and correlations between how children relate meaning and gestures, we may periodically add “power-ups”. For example, we might observe that children often grab at an object and then move their hand about. From such an observation, we may choose to make objects move around whenever children grab them.
We then observe over time whether children make use of any given power-up. If not, we remove it. Our goal is not to add any specific features, but to learn over time what children actually do when they have the opportunity to communicate with each other with visually augmented gestures.
By taking such an approach, we are guaranteed that the language which evolves out of this process will be naturally learnable by future generations of children.
How can we prototype this?
At some point, implementation of Future Language will need to move past a discussion of principles, and into the empirical stage. This will require an actual hardware and software implementation.
Unfortunately, the hardware support to make all of this happen does not quite yet exist in a way that is accessible to a large population. Yet it can be created in the laboratory.
Kids don’t need to be wearing future augmented reality glasses to be able to hold visually augmented conversations with other kids. They just need to be able to have the experience of doing so.
For this purpose we can use large projection screens that allow kids to face each other, placing cameras directly behind those screens so that our young conversants can look directly into each others’ eyes. We can also place a number of depth cameras behind and around each screen, and use machine learning to help us convert that depth data into head, hand and finger positions.
When this setup is properly implemented, the effect for each participant will be as though they are facing their friend, while glowing visualizations float in the air between them. They will be able to use their own gaze direction and hand gestures to create, control and manipulate those visualizations.
What we learn from this experimental set-up can then be applied to next-gen consumer level wearables, when that technology becomes widely available. At that point, our large screen will be replaced by lightweight wearable technology that will look like an ordinary pair of glasses.
Little kids will simply take those glasses for granted, just as little kids now take SmartPhones for granted. All tracking of head, eye gaze and hand gestures will be done via cameras that are built directly into the frames.
The eye worn device itself will have only modest processing power, sufficient to capture 3D shapes and to display animated 3D graphical figures. Those computations will be continually augmented by a SmartPhone-like device in the user’s pocket, which will use machine learning to rapidly convert those 3D shapes into hand and finger positions. That intermediate device will in turn be in continual communication with the Cloud, which will perform high level tasks of semantic interpretation.
The transition to a widely available lightweight consumer level platform will take a few years. Meanwhile, nothing prevents us from starting to build laboratory prototypes right now, and thereby begin our empirical exploration of Future Language.
It is important to do this now, because while we are not yet quite at the point where cameras built into eyeglasses that are affordable by anybody can recognize our hand and finger gestures with high accuracy and high speed, we will get there sometime in the next few years.
When that happens, hand and finger gestures will start to become incorporated into the ways that we communicate to computers, and communicate with each other through those computers. Gestural language will gradually become more integrated with verbal speech.
Eventually what we call language will be different from what we call language today. We will start to think of hand gestures and verbal speech as simply different aspects of a much richer continuum of communication between people.
Annotated Objects
What about annotation of physical objects? When we have all replaced our smartphones by ubiquitous future blended reality glasses, will we annotate the objects in our daily lives? And if so, how and why?
When we walk into a grocery store will we see other people’s ratings of each product, with some sort of visual indication of upvotes and downvotes?
Similarly, when we go to a museum or art gallery, will we see annotations telling us which art other people liked? And will we be able to filter those results?
For example, suppose I want to know what works of art in some museum were of particular interest to computer science professors. Will I be able to be directed to those pieces?
Perhaps there will be a rating of the quality of our tea. Or perhaps there will be a bit of text floating over the cup to tell us when it is just the right temperature to drink.
Face to face XR conversation with someone who is far away
It is clear what all this will look like when two people are in the same room. But what about when they are geographically separated? Since we are already wearing those glasses, it would be redundant to also require cameras and computer screens everywhere.
Currently, in order to have a video teleconference with another person, it is necessary for each participant to be facing an external camera that is pointed toward that participant. That camera might be mounted on a computer, on a smartphone or on a camera stand.
The Apple Vision Pro gets around this by providing a virtual avatar of the other person, which digitally approximates their appearance and facial expression. But as we learned during the COVID-19 pandemic, people prefer to see the actual person they are talking to, rather than any digital approximation.
I suggest that instead, each participant should just position themself in front of an ordinary mirror. They can then each see a view of each other, as though speaking with one another through a clear window.
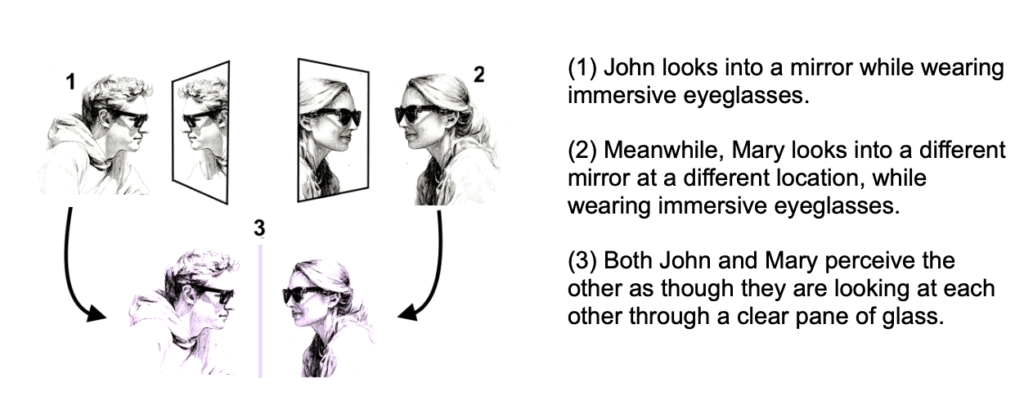
Some technical details:
1 Each participant looks through their eyeglasses and faces their own mirror.
2 The IMU and front-facing rgb and depth cameras of each participant are used to track the 6DOF position/orientation of that participant via standard VIO tracking, and also to create an RGBD (red,green,blue + depth) video stream of that participant.
3 That video stream is compressed and transmitted via an internet connection to the other participant.
4 The computer in the other participant’s wearable decompresses the RGBD video stream and displays it from the viewpoint of the other participant.
If we want to implement this sooner with less expensive XR glasses, the externally facing camera could just be an RGB camera, not a depth camera. Each participant would then appear to the other participant as a flat video floating behind the plane of the mirror.